Overview
The National Income and Product Accounts, or NIPA (also referred to as System of National Accounts, or SNA, outside of the United States), were a radical advance in economic measurement when they were instituted in the early 20th century. These accounts track aggregate output and income for the national economy. Most notably, they measure Gross Domestic Product and the quarterly fluctuations in GDP that tell us if the economy is growing or contracting. Before their advent, ascertaining the health of the economy was an inexact and patchwork procedure.
Download FileDisaggregating Growth Report
Great achievement though it was, even the creators of NIPA knew it had limitations. One of these is the lack of data on how income is distributed. In a section titled “Uses and Abuses of National Income Measurements,” the 1934 report to Congress that is the first official measurement of national income noted that “The welfare of a nation can, therefore, scarcely be inferred from a measurement of national income.”1 The author, future Nobel Laureate Simon Kuznets, was careful to differentiate between the idea of aggregate economic output and “economic welfare.”
The lack of data on how income is distributed is especially glaring now in the face of rapidly increasing economic inequality. Through much of the mid-20th century, economic growth was shared relatively equally by all income groups. Starting around the 1980s, however, larger shares of economic growth flowed to the top of the income distribution, with the top 1 percent experiencing especially large gains. According to the economists Thomas Piketty at the Paris School of Economics and Emmanuel Saez and Gabriel Zucman at the University of California, Berkeley, pretax income growth for the top 1 percent of all earners between 1980 and 2014 was 204 percent in the United States, far above the national average of 61 percent.2
NIPA needs some renovations to update it for the 21st century. Other researchers have suggested a broad range of possible improvements. Most notably, former French President Nicolas Sarkozy commissioned Nobel Laureates Joseph Stiglitz and Amartya Sen of Harvard University and economist Jean-Paul Fitoussi at the Institut d’Études Politiques de Paris to suggest how GDP could be rethought to more accurately measure economic and social progress. The resulting report contains a long list of suggested improvements, with suggestions that address inequality as well as thoughts on how environmental quality and life satisfaction could be better accounted for in national economic statistics.
This report sets a more modest but equally important goal: Instead of revolutionizing GDP, U.S. policymakers should evolutionize it. The pages that follow explain why the United States needs to add an explicitly distributional component to GDP and discuss how that goal can be accomplished. Adding a measure of how income is distributed would allow us to quantify inequality in our economy, and, in its most advanced format, would let U.S. statistical agencies disaggregate economic growth to see how the economy is performing for subgroups of people according to their income, geographical location, gender, and more. Being able to do so would enable policymakers at federal, state, and local levels to better understand the consequences of rising economic inequality and design policies that encourage more equitable and sustainable economic growth.
The time to make these improvements to NIPA is now. On a purely pragmatic level, methodological advances and increased availability of computational power make it practical to produce a more sophisticated NIPA. But even in the 1930s, economists understood that NIPA should eventually incorporate distributional data. Doing so responds to an emerging economic challenge: In recent years, the share of income that accrues to the top 1 percent has reached pre-Great Depression heights, creating a new class of super-rich individuals who enjoy much faster income growth than the “merely” rich and everyone else in society today.
This report proceeds in three parts. The first section describes the historical development of NIPA and recent efforts to update NIPA to reflect new economic realities. The second section explains why distributing national income is important. And the final section enumerates the desirable features that a distributional system of national accounts should have and discusses implementation of these features in the United States.
How one number became the sole marker of economic progress

For decades, our politicians and journalists turned to one number to assess economic welfare: GDP or gross domestic product, which measures total goods and services produced in a nation. Our national preoccupation with GDP and the worldwide standardization of GDP as a measure of a country’s economic fortunes results today in policies justified by the economic maxim of “growing the pie.” But GDP was never intended to measure welfare. For that, we need to understand how the economic pie is distributed. Insufficient attention has been paid to income distribution, and over the past several decades this inattention has resulted in the vast majority of Americans registering spartan income gains while the rich enjoy rapid growth.
Increases in inequality demonstrate why one number is no longer adequate to track the economic fortunes of our nation. While GDP captures what happens in the aggregate, the central economic issue of our time is how income growth has diverged between those at the top of the income spectrum and the rest of society. GDP is insufficient to understand this phenomenon, which in turn means economists and policymakers alike can neither clearly understand the effects of income inequality on the broader economy nor fashion more equitable economic policies that result in broad-based and sustainable economic growth.
The U.S. economy in the 21st century is characterized by stagnant incomes for the vast majority of workers while incomes at the very top rise rapidly. Income inequality began to rise in the mid-1980s, and the growing gap between the top 20 pecent on the income ladder and those underneath was well known by the early 1990s. But the rise of the top 1 percent was not as well-studied because economists had no data on the incomes of the richest members of society.3 Daniel Feenberg at the National Bureau of Economic Research and James Poterba at the Massachusetts Institute of Technology-authors of one of the first academic studies to accurately document the rising fortunes of those at the very top of the economic ladder-noted that “the economic lives of the rich, especially the rich who are not famous, are something of a mystery.”4
Although academics gamely attempted to fill in the gaps, official economic statistics released by the U.S. government missed the sudden explosion of gains among the top 1 percent, whose share of national income nearly doubled between 1980 and the early 2000s. In part this is because many of the federal statistical agencies that track the nation’s economic fortunes traditionally focus on aggregate rather than distributional measures of well-being. Moreover, these same agencies do not have access to the necessary data to show income changes at the very top of the income distribution. The federal statistical infrastructure, which once led the world in producing high-quality estimates of economic phenomena, was largely developed in the mid-20th century. While these products are now measured more accurately, in many cases their essential nature has not changed. (See the appendix for a comparison of U.S. Bureau of Economic Analysis releases from 1967 and 2017.) This is true of our most significant and well-known statistical product, the National Income and Product Accounts.
NIPA: A significant advance in economic record keeping in the United States
GDP is one component of the United States’ National Income and Product Accounts. The NIPA is an accounting of the monetary value of all output produced in the United States and by U.S. nationals that uses double-entry accounting: Total output is tabulated both as income and as spending on goods and services produced. The Bureau of Economic Analysis reports the results of this tabulation quarterly.
The headline statistic of the NIPA is GDP, and the quarterly releases are primarily known for their estimates of GDP growth over the preceding three months. But there is a great deal more detail available-one can look up the change in output of motor vehicles, for example, or the change in spending on imported goods, and GDP growth is geographically disaggregated at the county level. The statistical infrastructure behind the NIPA is considerable. BEA uses surveys and administrative data from the U.S. Census Bureau, the Internal Revenue Service, the Department of Labor’s Bureau of Labor Statistics, and the U.S. Department of Agriculture.
Credit for development of the NIPA is generally given to economist and Nobel Laureate Simon Kuznets, who came to the Commerce Department from the National Bureau of Economic Research. Academics, research organizations, and even federal agencies had made estimates of national income before Kuznets did, but his work would be institutionalized and become the official national income product of the federal government.5
The impetus for Kuznets’ initial work was a resolution introduced by Sen. Robert La Follette of Wisconsin, making the Department of Commerce responsible for reporting out estimates of national income for 1929-1931. National income was not a new concept, but it’s easy to imagine why it finally gathered legislative backing in 1932, shortly after the election of Franklin D. Roosevelt as president and just a few years after the onset of the Great Depression. Kuznets submitted a study of the requested years in January 1934. It painted a stark picture of the devastation wrought by the Great Depression: The report showed that national income had dropped more than 50 percent.6
Entry of the United States into World War II further enhanced the stature of Kuznets and the NIPA, which is frequently credited as a major asset to the war effort.7 Over time, GDP superseded Gross National Product as the headline statistic of NIPA because it captures all output produced within a nation, regardless of ownership. In 1953, building on success in the United States, the United Nations published its standards for Systems of National Accounts under the guidance of economist Richard Stone. This standard provides guidelines for a uniform measurement of GDP used by nations across the globe.
In the decades since, GDP has become the de facto standard for measuring economic progress of nations worldwide. It has attained a unique level of authority to the exclusion of other markers of a nation’s development. Official determinations that the U.S. economy is in recession are based in part on GDP growth. After the Great Recession, the deviation from the GDP trend was used to suggest the appropriate size of a government stimulus package.8 Aspirants to the presidency promise higher GDP growth,9 and the president’s economic promises revolve around a growth target.10 We appear to be addicted to GDP.11
Adding a distributional component to the NIPA would not replace GDP or the measure of GDP growth. It would instead add additional context by providing information on income growth for, for example, the bottom 50 percent of earners or the top 10 percent. These measures would allow us to better understand who is benefitting from economic growth.
Measuring inequality in the national accounts is necessary and overdue

Although there remains some disagreement among U.S. policymakers about whether and how economic inequality should be addressed with policy and what the exact magnitude of the rise in inequality is, the fact of rising inequality has broad consensus. By one estimate, the magnitude of this change has returned the U.S. economy to levels of inequality last seen prior to the Great Depression. (See Figure 1.)
Figure 1
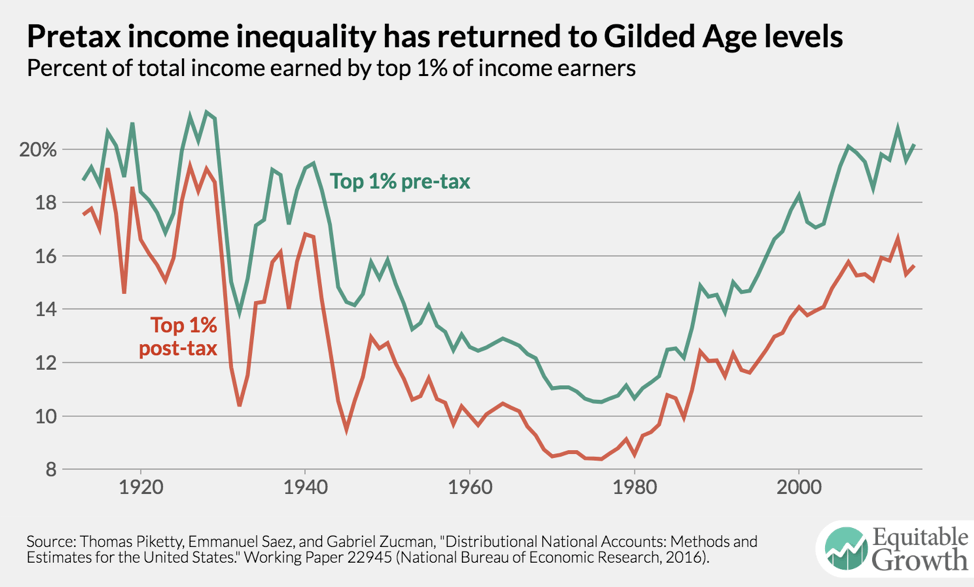
A change in the underlying fundamentals of the U.S. economy of this magnitude demands scrutiny. Following the lead of economists Piketty, Saez, and Zucman, this report refers to a system of national accounts that prominently features a distributional component as distributional accounts. At its most basic level, distributional accounts would provide data like that used to construct Figure 1. Most importantly, it would report how much income grew for people at different parts of the income curve to grant context to the overall GDP growth number. But it should also report, for example, what share of all economic output is earned by income groups within the population to provide a current snapshot of inequality in the economy.
The distribution of growth should be measured by the federal government and given equal billing to GDP growth
The United States needs to measure the distribution of growth in the economy. Current measures are disjointed, without discussion of how growth and inequality are related even though Kuznets prominently features discussion of the importance of this relationship in the very first estimates of national income. Most obviously and urgently, governance that promotes more equitable economic growth is impossible if the distribution of growth is unmeasured. Policymakers are eager to wade into the inequality debate now, but policy that targets inequality can’t be evaluated without an improvement in how we measure the distribution of economic progress. The current one-number-fits-all approach of measuring GDP without distributional data supports the antiquated idea of “growing the pie” without understanding where the pie goes. Aggregate GDP growth alone gives people a misleading idea of the health of the economy.
Even as advocates mobilize for policies that could promote more equitable growth and as politicians declare their desire to combat economic inequality, little has been done to improve measurement of the phenomenon. It is accordingly unclear how these actors will know that their policy proposals are working to create more equitable growth. The Piketty, Saez, and Zucman academic team has created the most comprehensive estimates of inequality in the United States to date. These economists have rendered a formidable service, but their research depends on access to federal data that may not last, and there is no guarantee that any team of researchers can maintain indefinite updates to a dataset. Institutionalizing this duty with a federal agency is the only way to guarantee the creation of a consistent, long-lasting dataset.
Adding a measure of inequality to the federal statistical reporting system confers legitimacy to the phenomenon. In the words of the Stiglitz-Sen-Fitoussi Commission, “What we measure affects what we do.”18 Nowhere is this more dramatic than in the reporting of GDP growth. The simple act of measuring GDP has led the media, the public, and at times academia to focus on economic growth to the exclusion of any other concern. For decades, it has been assumed that “growing the pie” should be the foremost goal of economic policy, while little attention is paid to whether that growth is shared by all Americans and results in more sustainable economic growth. This report now turns in more detail to the inadequacies of GDP as the only measurement of economic growth.
Reporting GDP growth without a distributional component is misleading
Reporting national output growth without a distributional component can be deeply misleading if it is not carefully interpreted. The experience of workers at different levels of income often is vastly different-indeed, it would have to be for inequality to increase, as we have seen in the United States. The fortunes of earners at the very top of the income distribution could be gaining while those in other parts of the distribution see no income growth or even negative income growth. And this could be consistent with positive or negative national economic growth. (See Figure 2.)
Figure 2
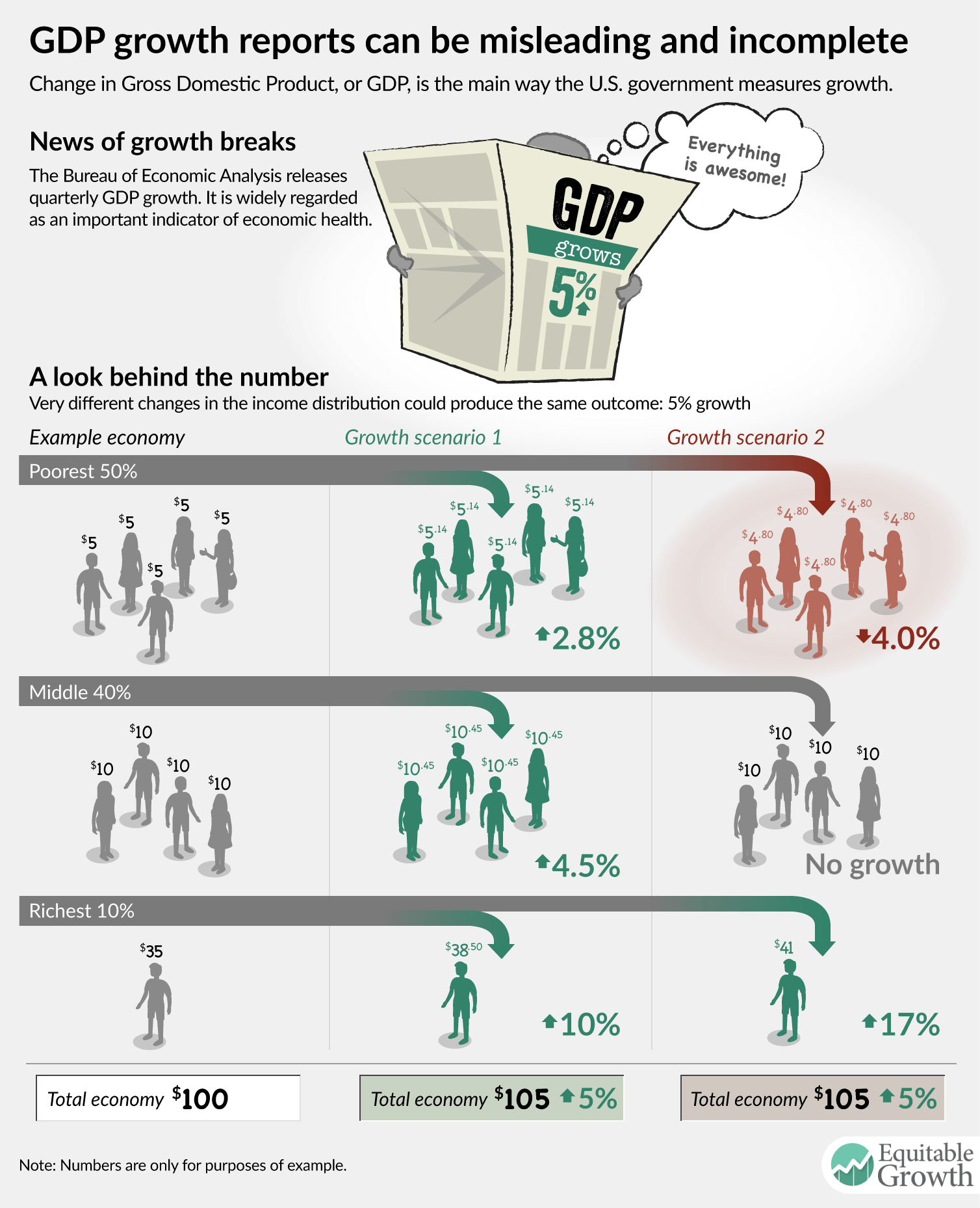
The official GDP growth statistic may have very little correspondence to the experience of a statistically average or demographically numerous American. This is especially true when incomes at the very top are diverging because a small number of people at the very top of the income distribution are in control of a significant share of the nation’s output, increasing the chance that fluctuations in their income will substantially affect the aggregate. In fact, the average income growth for each 1 percent-slice of the income for the entire country is higher than the actual amount of growth for all but the top 10 percent of earners. GDP growth is a report of average growth across everyone in the United States, but as incomes at the very top skyrocket, they drag the average up with them, making it less and less representational of a truly “average” person. (See Figure 3.)
Figure 3
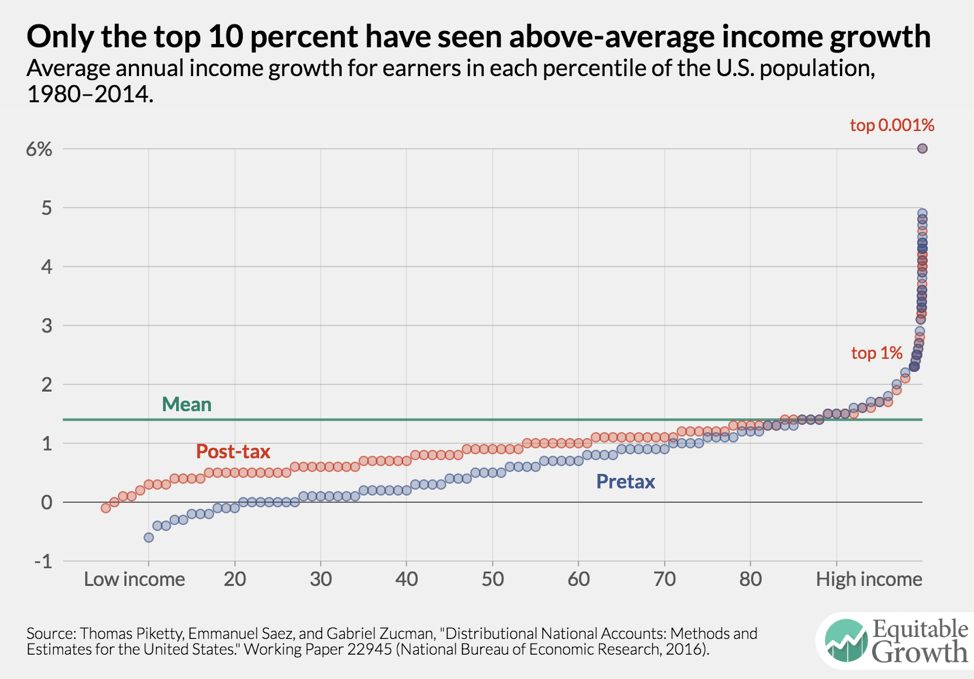
The existing U.S. economic statistical infrastructure is insufficient to understand inequality
Good measurement is important to any policy agenda that aims to address growing inequality. The “streetlight effect”-named for an old joke about a drunk on a dark night who searches for his lost keys only under a streetlight because that’s where the light is-describes the phenomenon where researchers understudy a problem because there is insufficient data on it. Lack of good data resulted in U.S. economists largely missing the phenomenon of booming incomes at the top 1 percent of the income distribution for several years. Official inequality statistics will encourage economic and policy research on the causes and effects of economic inequality, providing us with actionable intelligence for managing the economy in the 21st century.
Existing measurements of inequality by federal agencies in the United States are insufficient to the task. Existing measurements fail for one of the following reasons:
- They are released in an ad-hoc way or are not given the level of attention that NIPA is, dooming them to obscurity. The quarterly NIPA releases of GDP growth occupy a place of primacy in the economic imagination of journalists and the public that can’t be matched by the occasional working paper.
- They aren’t comparable to the NIPA accounts, making it impossible to decompose total national output by income bracket.
- They don’t capture the income of extremely rich individuals.
- They don’t attempt to document inequality along demographic lines. We know little, for example, about within-group inequality for specific racial and ethnic groups.
Current federal efforts to measure inequality are briefly described below. The leading academic effort is also discussed.
Academia
Economists Thomas Piketty, Emmanuel Saez, and Gabriel Zucman have released the most comprehensive estimates of inequality in the United States to date.19 They have worked closely with the Internal Revenue Service to utilize tax-return data that makes their source data extremely accurate for even very small slivers of the population: They report income shares of the top 0.001 percent of earners. Importantly, their measurement is compatible with NIPA. Adding up total income of all individuals in their dataset will produce National Income. The authors hope to release microdata that can be used by other researchers to perform their own analyses. These estimates lag by as little as one year. In July 2016, for example, they released estimates for inequality in 2015.
Congressional Budget Office
The CBO releases an approximately annual report, “The Distribution of Household Income and Federal Taxes” that covers market income, government transfers to citizens such as Supplemental Nutrition Assistance, and taxes for quintiles of the population and the top 1 percent of earners.20 This report comes closest to approximating the results of the academic team in that it accounts for both pretax and post-tax income and is able to capture the top 1 percent of earners. CBO does not attempt to capture all output in NIPA, however, so while these estimates are better than others, they remain incomplete and are not comparable to the changes in growth obtained from NIPA. The CBO dataset begins in 1979 and is generally released on a three-year lag. Estimates for inequality in 2013, for example, were released in June 2016.
Census Bureau
The Census Bureau issues an annual report “Income and Poverty in the United States” that covers money income.21 Money income is a slightly unusual measure in that it includes some government transfers but excludes others and does not include some forms of compensation such as employer-provided health insurance. It also does not reflect taxation. Income shares are reported by quintile, with the top 5 percent broken out separately. Because this report is based on the Current Population Survey, which does not adequately capture high-income individuals, it does not give a complete picture of income inequality in the United States.
Bureau of Labor Statistics
The BLS conducts the annual Consumer Expenditure survey, which provides estimates of how much U.S. consumers are spending on different types of goods. It includes distributional tables for the results that divide consumers into deciles and provide levels and shares of expenditures on each product category for each decile.22 This product provides a measure of consumption by income deciles and can be used to create measures of consumption inequality.
Federal Reserve Board
The U.S. central bank conducts the Survey of Consumer Finances every three years. This survey tabulates financial assets held by respondents. The Federal Reserve reports the distribution of these assets by quintiles, with the top 10 percent broken out separately. The percent of families who have assets in each category is reported, along with the mean and median value of those assets (for families with assets only).23 This survey would be the primary source of data for any attempt to track wealth inequality.
Sophisticated distributional accounts will help policymakers build a more equitable economy and more sustainable economic growth
An even more ambitious goal is to report disaggregated growth statistics that allow for the analysis of growth according to geographical boundaries, gender, and race and ethnicity. Distributional accounts with this degree of sophistication would allow policymakers to disaggregate growth in a uniform manner and look at trends in income for cross sections of the population.
Being able to disaggregate growth in this way promises to be meaningful to people in communities all across the country in a way that the NIPA is not. The aggregate economic statistics reported today are increasingly disconnected from the experience of the average worker. Since 1992, the United States has experienced two of the longest periods of economic growth in its history. Unemployment fell below 4 percent in 2000 and more recently reached lows very close to 4 percent. Growth has been modest by historical standards, but the picture painted by our headline economic statistics is nonetheless positive.
And yet, in this same era, income growth has been incredibly tepid for many Americans. According to Piketty, Saez, and Zucman, the bottom 50 percent of individuals have seen their pretax incomes grow by just 1 percent between 1980 and 2014, after accounting for inflation. For tens of millions of Americans, the headline economic statistics are simply irrelevant to their lives. Our economic statistical infrastructure does not capture this runaway growth in the top 1 percent and is not linked to GDP, preventing us from considering inequality and growth in combination.
Pundits like to talk about the economic devastation of the rust belt, but while growth is measurable in each state and county, policymakers know relatively little about how growth in a geographic region is distributed across income groups.24 Similarly, policymakers know from looking at unemployment statistics that black Americans experience the economy very differently, as their unemployment rate is nearly twice that of white Americans. But policymakers are unable to discern whether African Americans at the bottom and in the middle of the income distribution have fared better or worse than whites or Hispanics. These data simply don’t exist. Recent research has only just begun to explore this kind of disaggregation.25
If a primary government policy goal is to describe the economic fortunes of all Americans, and if it is important to be able to target policy at the state level and toward those Americans who are struggling more than their peers, then policymakers should undertake the construction of sophisticated distributional accounts that disaggregates growth along several demographic lines, just as the Bureau of Economic Analysis currently does for aggregates across states and counties.
Implementing distributional accounts

The Bureau of Economic Analysis oversees creating the NIPA and should also be responsible for adding a distributional component to it. The BEA already provides breakdowns of growth by industry and by geography; breaking growth down by income groups is a natural extension. In fact, the agency has measured inequality before: Starting in 1947, it tracked the distribution of income between quintiles of the economy as a supplement to the NIPA. Through 1956, when the agency stopped tracking these data, the distribution of income was steady, reflecting shared economic prosperity. (See Figure 4.)26
Figure 4

The BEA stopped compiling these data due to lack of resources, but recently new data for 2000, 2006, and 2012 have appeared in the BEA’s journal Survey of Current Business.27 The agency has expanded its production of regional and industry accounts and has even requested new funding to expand into household accounts. It would be a natural extension to have BEA produce distributional accounts as it has done in the past.
Methodological and political hurdles
It is technically possible to add a statistical abstract of income distribution to the NIPA right now. There are methods and data available to produce these distributional accounts. Many other countries have started releasing these measures. The most immediate obstacle to distributional accounts in the United States is that data are not being shared well across U.S. government agencies. To understand what would be required to change this, it is helpful to know a little bit about how a system of distributional accounts would be constructed.
Overview of methodology
Traditionally, income at the person level in the United States is measured using the Current Population Survey’s Annual Social and Economic Supplement, or CPS. This supplement asks respondents to report their income in many different categories over the past year. The CPS is a high-quality survey, but it does a poor job of capturing individuals at the very top of the income distribution. Any distributional analysis that only uses the CPS will fail to capture high-income individuals and will not accurately reflect the income of the top 5 percent or so of earners in the economy.
One solution is to use the CPS in concert with administrative tax-return data from the IRS. The administrative data are nearly comprehensive (non-tax-filers are of course mostly absent) and can be matched to the CPS data to account for nonfilers and to impute certain transfers and benefits that are not captured in the tax data. Combining these two sources of data is the approach taken by Piketty, Saez, and Zucman in constructing their Distributional National Accounts dataset.
This report does not attempt to address the many outstanding methodological debates inherent in this approach. Assumptions must be made about tax incidence-what portion of taxes are paid by workers versus employers-as well as the allotment of public goods such as education spending and the allotment of the federal debt. Decisions must be made about how to impute the value of certain transfer programs and rents to homeowners. These questions can be complex and are not yet settled, but are beyond the scope of this report.28
IRS tax-return data are generally not shared with other federal agencies
While CPS data are easily available to anyone, access to the IRS’s tax-return data is governed by U.S. code, and very few federal agencies are allowed access. Title 26 of the U.S. code designates which agencies will receive access. BEA is among these agencies, but it is granted access only to the tax returns of corporations.29 The Census Bureau (also housed in the Department of Commerce) does receive the individual tax-return data, although it gets an abstract with a limited amount of income data.
To create estimates of inequality linked to the NIPA, BEA needs administrative tax-return data from the IRS. There are a number of ways such access could be granted to BEA and different avenues of encouraging data sharing between federal agencies should be explored.
The 2017 final report of the congressionally mandated Commission on Evidence-Based Policymaking demonstrates that bipartisan support exists for alterations to current data-sharing policies at the federal level to make new types of research possible. Recommendations 2 through 4 from the report, if implemented, could directly aid the cause of creating distributional national accounts by considerably reducing the barriers to researchers accessing tax-return data from IRS’s Statistic of Income division.30
Legislative action will almost certainly be necessary to give BEA access to the original IRS data. But the agency does not require any further legislative authorization to create a distributional component to the NIPA or to distribute it with the quarterly NIPA releases.
Desirable features and feasibility
To this point in our report, the actual form a distributional component of the NIPA would take has been left vague. There are several approaches the BEA could take, many of which would be reasonable starting points. In this section, we highlight some features that should be included in strong distributional accounts. Some will not be easily achieved, but once the data hurdles described above are resolved, most of these could be achieved in time.
What should be released?
The simplest option for publishing distributional national accounts data is for the federal government to publish a broad array of summary statistics. These might take the form of GDP growth statistics for several income groups, say the bottom 10 percent and the top 1 percent. BEA already disaggregates growth by geography and could add a distributional component to this effort as well. If possible, growth should also be disaggregated by demographic characteristics.
These summary statistics would be derived from a much larger dataset consisting of tax data linked to the CPS and other sources. This microdata could be extremely useful to government and nongovernment researchers alike. While BEA would not be able to publicly release this linked dataset due to privacy concerns, it may still be possible for BEA to make it accessible for appropriate researchers. If the Commission on Evidence-Based Policymaking’s recommendation for a National Secure Data Service is adopted, then the microdata could be released through it. Alternately, BEA could explore the creation of a synthetic dataset based on the microdata that could be distributed more broadly. Researchers in the IRS are already exploring the possibility of synthetic tax-return data, which could aid this effort.
Choice of income measurement
In the mid-20th century, nations tended to favor reporting Gross National Product, or GNP. As globalization resulted in multinational companies with branches around the world, GNP gave way to Gross Domestic Product, which counts production within a country’s borders by foreign-owned companies in national output and excludes production by domestically owned companies in foreign countries.
For the purposes of tracking the distribution of income growth, however, both GDP and GNP have disadvantages. GDP includes incomes earned by foreign companies and thus can be misleading about the incomes of the domestic population. GNP addresses this concern, as it excludes income attributable to foreign firms and includes incomes attributable to domestic firms. But there are other modifications we might wish to make to GNP to better capture the income of individuals in the economy. Notably, both GDP and GNP are measured gross of depreciation. In other words, GDP and GNP are not reduced to reflect the decline in the value of durable goods (equipment, structures, and so forth) due to use and the passage of time.
The Stiglitz-Sen-Fitoussi Commission report thus favors moving to Net National Income, or NNI. Piketty, Saez, and Zucman also use NNI as the basis for their Distributional National Accounts dataset. NNI is GNP minus depreciation and indirect taxes. Depreciation of capital is not income that accrues to an individual in any traditional sense, so it makes sense to exclude this from a distributional analysis.
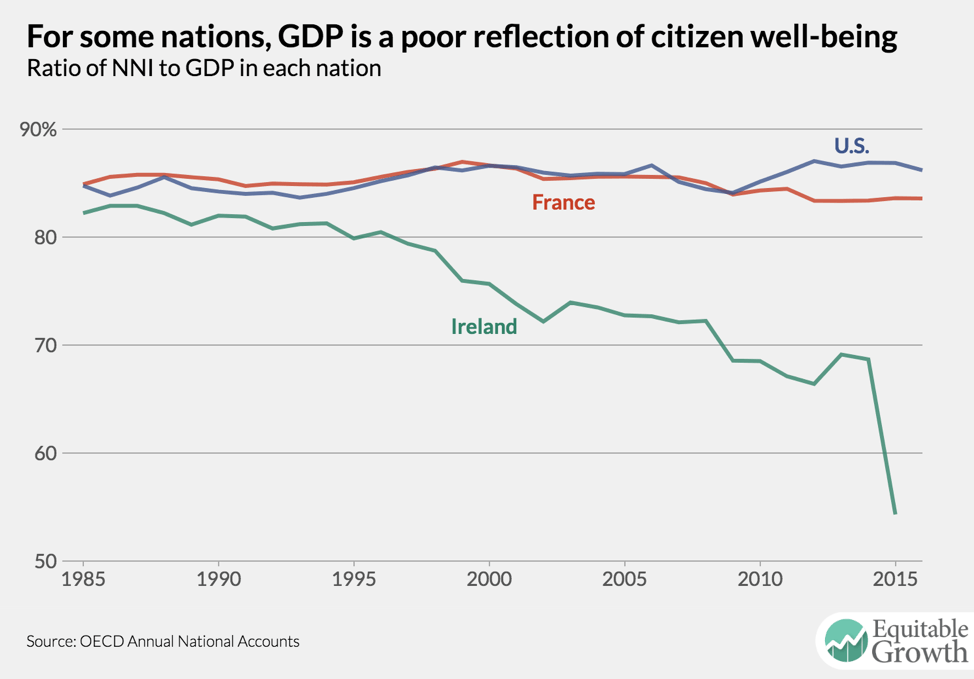
The Stiglitz-Sen-Fitoussi Commission illustrates well the advantages of NNI. Consider the ratio of NNI to the GDP of Ireland, France, and the United States. The relationship between the two measures in Ireland diverges from France and the United States because a huge share of Ireland’s economy is corporate profit being shielded from high taxes. If we are interested in assessing the well-being of people in the nation, it makes little sense to allot these profits to the people of Ireland, as they have little real positive impact on incomes in the country. (See Figure 5.)
Figure 5
It may be desirable to refine the notion of income even further, but using NNI is a reasonable place to start. Regardless of what income concept we target as the aggregate measure of all income in a nation, an important consideration when we begin to break that measure down and create distributional measures is how we assign that income to individuals. In particular, we need to think about the distribution of income before and after government interventions.
Pretax and post-tax and transfer
To properly evaluate a country’s policy response to rising economic inequality, we need to know how unequal incomes are before and after taxes and transfers. It is frequently pointed out that income inequality in the United States before taxes and transfers, while high, is not a significant outlier compared to other nations. But the United States does much less to redistribute income through taxes and transfers, making it one of the most unequal countries by this measure. (See Figure 6.)
Figure 6
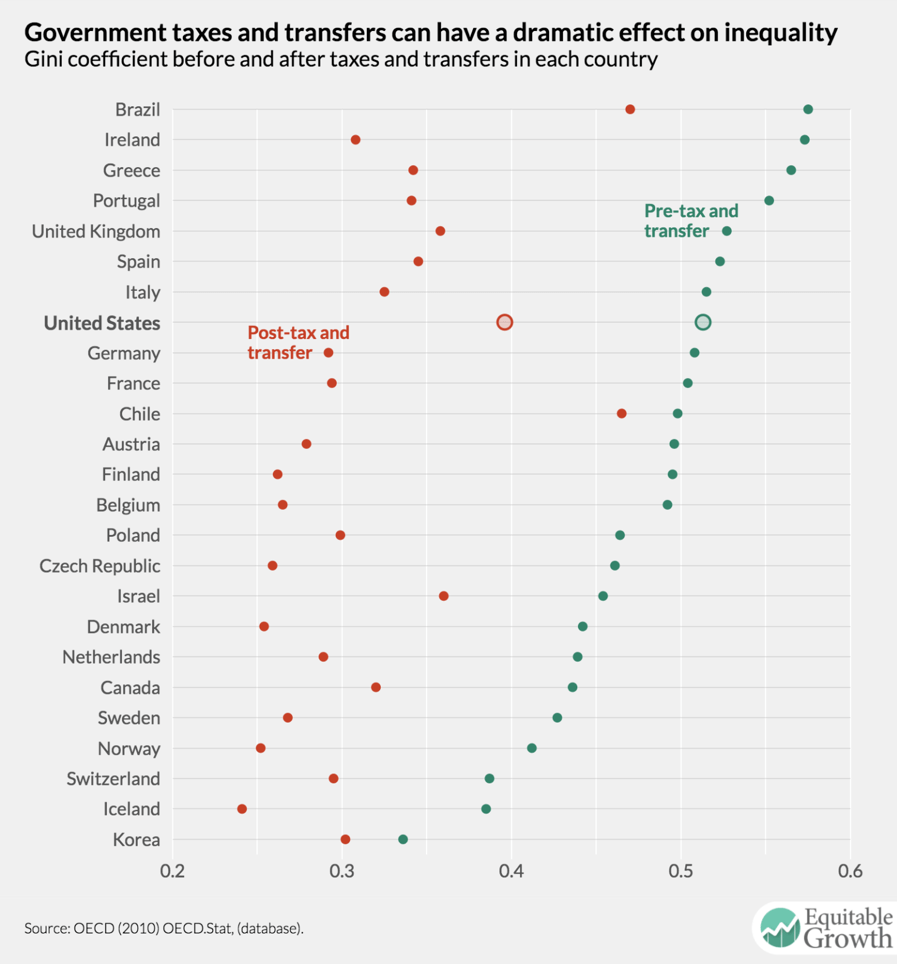
Both measures tell policymakers and economists something interesting about the economy and the nation’s policy regime. Although some assumptions need to be made, calculating both is not a significant methodological hurdle. Participation in transfer programs can be imputed using surveys of government benefits. To calculate pretax income, some assumptions must be made about tax incidence. Issuing microdata would allow researchers to make their own assumptions about tax incidence, but relatively noncontroversial choices could be made in the release of a statistical abstract of the data.36
Percentiles of income addressed
Perhaps the most significant shortcoming of existing distributional measures of income is that most use coarse buckets to group individuals by income. In the Census Bureau’s annual income and poverty release, for example, it looks at the share of income that flows to each of five quintiles of the income distribution. Recent work by academic economists demonstrates that we must look at much finer quantiles to capture the most dramatic income shifts in the economy.
Figure 3 above is derived from the Distributional National Accounts dataset created by Piketty, Saez, and Zucman. It shows growth between 1980 and 2014 at every 1 percent increment in the income distribution and further subdivides the top 1 percent into the top 0.1 percent, 0.01 percent, and 0.001 percent. Notice that earners in the top 90th percentile enjoy a growth rate only slightly above the average for the entire population. As this report has already pointed out, the average in this case is extremely misleading. Most of the overall growth is being driven by gains at the very top of the 1 percent of income earners.
Even dividing the income distribution into deciles is insufficient. At the very least, it is necessary to see the top 1 percent of the income distribution to fully characterize the extent of inequality in the United States. Luckily, this is simple if the methodology described at the beginning of this section is followed. By using the IRS tax data, researchers can look at arbitrarily small slices of the population. This cannot be accomplished using the CPS data alone because the survey does not use a large enough sample to adequately capture dynamics in the long right tail of the income distribution.
Frequency of publication
Because GDP growth is reported quarterly, it is highly desirable to be able to disaggregate those growth statistics and report how growth is distributed in each quarter alongside GDP. This elevates distributional analysis to the same level of importance as aggregate output analysis. Related to the frequency of publication is the time lag on published estimates. Quarterly GDP growth is posted quickly-just one month after the end of the quarter. Those numbers are then revised in future releases and will change some as higher-quality data sources become available.
Using currently available tools, distributional accounts can neither be published as frequently nor with as short of a delay as GDP. This is attributable to the data sources used to build it. The CPS supplement is released once annually in March with data that cover the previous 12 months. The administrative data from the IRS is available once annually as well (since people file taxes once a year) but is only accurate with a considerable lag of at least one year. This is because some filers ask for extensions or simply file very late, and these filers are not randomly distributed. Wealthy taxpayers with complicated taxes are far more likely to request extensions and file their taxes late in the year.
If the analysis can be performed quickly, then distributional accounts could be released once annually with a one-year lag. In 2017, for example, the responsible federal statistical agency would be able to release a distributional analysis of GDP in 2016. Circumventing this limit will require the Bureau of Economic Analysis to use previous estimates and impute quarterly change based on some other data stream that is available to them. It is not currently clear how this would be done.
Wealth and consumption
Economists often talk about three different types of inequality. Income inequality is the most reported on, but wealth and consumption inequality also are important measures of how the economy is affecting different groups. Consumption inequality is generally lower than income inequality since a huge portion of the income of the very rich is saved (and becomes wealth). Wealth inequality in the United States is significantly higher than income inequality.
Both measures are interesting in their own right and give us a more complete picture of the distribution of resources in the U.S. economy. Ideally, they would be captured alongside income and reported in a similar level of detail. Research has shown that the top 5 percent has increased its share of both wealth and consumption in addition to income.37
Piketty, Saez, and Zucman already include wealth data from the Survey of Consumer Finances in their analysis of distributional accounts. The method for doing so is similar to that of merging CPS data into the tax-return data. A statistical match of the tax-return data is made to the Survey of Consumer Finances. The Consumer Expenditure Survey can likewise provide the basis for a measure of consumption inequality, although there are a number of methodological concerns with this survey.38 Efforts have been made to create a consumption series that is consistent with NIPA but due either to measurement error in the Consumer Expenditure Survey or error introduced when matching it to the CPS, these efforts have produced questionable results.39
Demographics
An ambitious extension to a system of distributional accounts is to add demographic detail sufficient to decompose growth along nonincome lines. Imagine the government reporting a growth percentage specific to the bottom 40 percent of women on the income distribution, for example, or the top 1 percent of black males. Growth could also be disaggregated along geographic lines, with distinct distributions reported for each state, large cities, or the several hundred metropolitan statistical areas in the United States. Geographic disaggregation is particularly desirable for what it could add to our ability to evaluate policy at the state level.
Besides being invaluable to academic researchers, disaggregating national income statistics along geographic, demographic, and economic lines will personalize the measurement of economic outcomes for many Americans. Conventional measures of aggregate economic growth ring hollow for many who wonder why they aren’t seeing progress and prosperity in their own lives. Making the analysis of subpopulations feasible could radically transform how we understand the impacts of economic policy.
This level of detail is attainable, although there are several hurdles to full implementation. For some demographic characteristics, the IRS data would have to be merged to Census datasets. The tax data lack most nonfilers, and the CPS sample is not nearly large enough to provide information on nonfilers in specific subgroups of the population. Nonfilers are generally in the bottom of the income distribution, so finer levels of disaggregation may require us to focus only on the middle and top of the distribution. Second, some government transfers must be imputed based on CPS data. At smaller levels of disaggregation, it may only be possible to report certain subsets of the data, with coarser quantiles and without all income included. There are also conceptual questions. For example, how should income be split between spouses if we are interested in examining income by gender? These are all hurdles requiring further consideration and analysis.
Conclusion
It is worth revisiting this line from the Stiglitz-Sen-Fitoussi Commission report one more time: “What we measure affects what we do.”40 This has certainly been true for the measurement of GDP, which has encouraged nations to focus on “growing the pie,” with the apparent assumption that a rising tide lifts all boats. This assumption is not borne out by the evidence. Economic growth has increasingly benefitted a tiny slice of the U.S. population. Even now, although we well know that the vast majority of Americans have not seen anything close to the headline GDP growth numbers, we continue to set GDP growth targets as if they can somehow guarantee prosperity for all by increasing a single number. They cannot.
Because we have not prioritized the measure of economic inequality, the rapid rise of the very rich went unheralded for years. When it was finally noticed, many more years passed before it had any significant impact on the national debate. Without adding a distributional component to our measurement of economic growth that is given equal billing to GDP growth, stewards of the economy will be half-blind when evaluating the overall economic health of the nation. Adding a distributional component to the NIPA is long past due, more akin to performing emergency surgery than preventative care.
Measuring inequality and reporting it in a major economic release will change how citizens, journalists, and policymakers think about the economy. It will force each of these audiences to consider whether growth is really enough if it leaves a significant fraction of the population behind. The good news is that the methodology is known. The data exist. The barriers to implementing a distributional system of national accounts in the United States are relatively low. Doing so will mark a significant advance in the nation’s economic record keeping that, similar to the establishment of the NIPA, will help guide policy in the nation for decades to come.
Appendix: Past and present BEA reports on GDP growth
Figure A.1: BEA’s quarterly announcement of GDP growth for the second quarter of 1967.
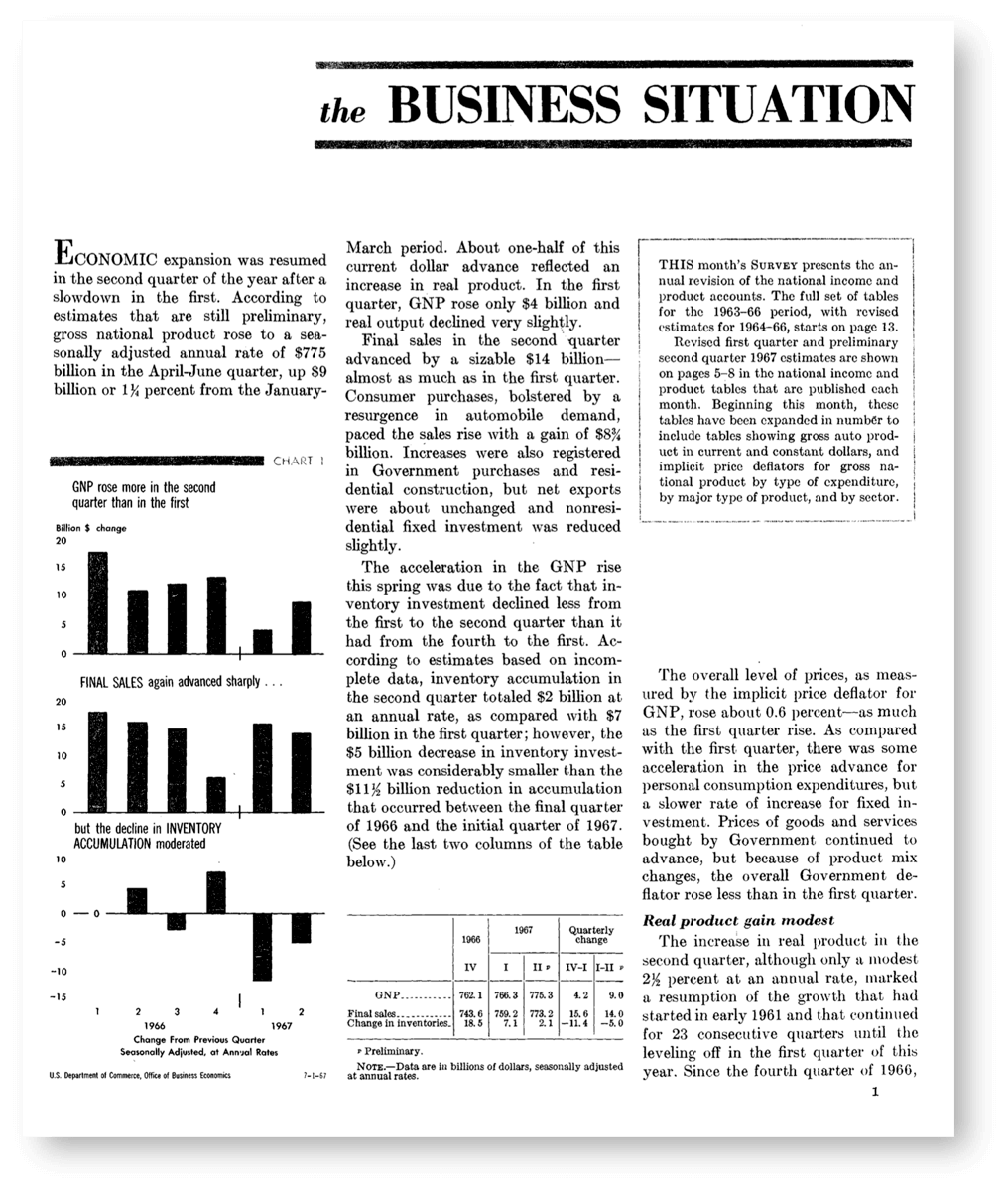
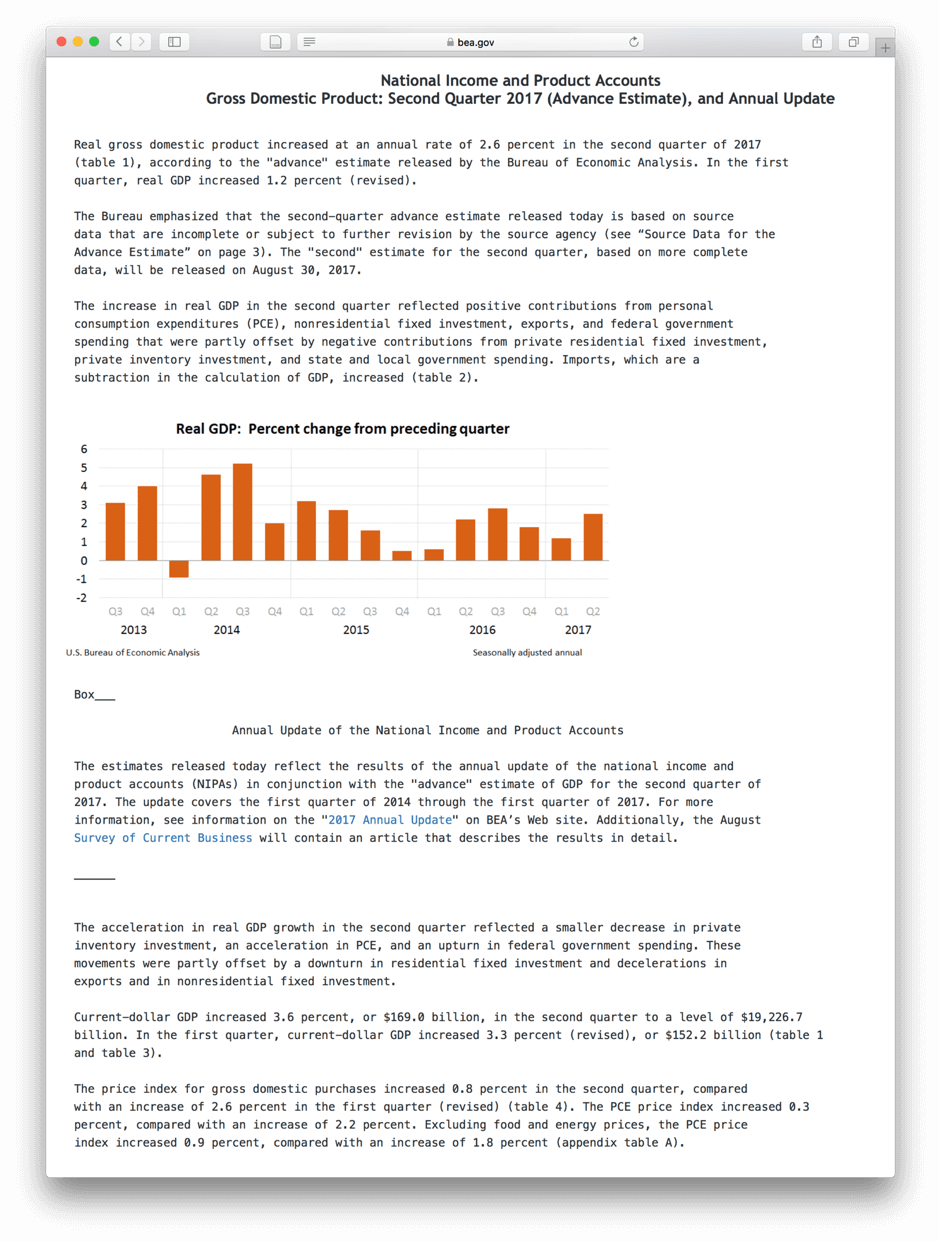
Figure A.2: BEA’s quarterly announcement of GDP growth for the second quarter of 2017.
End Notes
1. Simon Kuznets, “National Income, 1929-32” (Washington: U.S. Government Printing Office, 1934).
2. Piketty, Thomas, Emmanuel Saez, and Gabriel Zucman, “Distributional National Accounts: Methods and Estimates for the United States.” Quarterly Journal of Economics (2018, forthcoming).
3. Economists were aware of rising inequality in the early 1990s, but because they were relying on the Current Population Survey, which does not sufficiently sample the very rich, they did not understand how much growth was concentrated in the top 1 percent. The first authors to use administrative tax data, which can capture the very top of the income distribution, were Daniel R. Feenberg and James M. Poterba, “Income Inequality and The Incomes of Very High-Income Taxpayers: Evidence from Tax Returns.” In James M. Poterba, ed., Tax Policy and the Economy. (Cambridge: MIT Press, 1993).
4. Ibid., p. 146.
5. For a more comprehensive lineage see Carol S. Carson, “The History of the United States National Income and Product Accounts: The Development of an Analytical Tool,” Review of Income and Wealth 21 (2) (1975): 153-181.
6. Rosemary D. Marcuss and Richard E. Kane, “U.S. National Income and Product Statistics.” Survey (87) (2007): 32-46.
7. Ibid.
8. As an example of these calculations, see Paul Krugman, “Stimulus Math (wonkish),” The Conscience of a Liberal blog, November 10, 2008, available at https://krugman.blogs.nytimes.com/2008/11/10/stimulus-math-wonkish/?mcubz=0.
9. Jeb Bush suggested 4 percent. See Timothy Noah, “Jeb’s 4 percent solution,” Politico, June 15, 2015, available at http://www.politico.com/story/2015/06/jeb-bush-2016-economic-growth-4-percent-119042.
10. The White House, “Director Mulvaney: ‘Introducing MAGAnomics,’” News Clips, July 13, 2017, available at https://www.whitehouse.gov/the-press-office/2017/07/13/mulvaney-introducing-maganomics.
11. Measurement of national output is called the NIPA in the United States and the System of National Accounts in many other nations (after a standard published by the United Nations). We follow the convention of a literature that critiques these measures by referring to them generally as GDP when we are not referencing NIPA specifically. Although NIPA and SNA measure more than just GDP, GDP is the most visible part of national output and is emblematic of the one-number-fits-all approach that has drawn criticism throughout the history of national accounts.
12. Lorenzo Fioramonti, Gross Domestic Problem (New York: Palgrave Macmillan, 2013).
13. Simon Kuznets, “Economic Growth and Income Inequality,” American Economic Review (3) (1955): 1-28.
14. Robert F. Kennedy, “Remarks at the University of Kansas, March 18, 1968,” available at https://www.jfklibrary.org/Research/Research-Aids/Ready-Reference/RFK-Speeches/Remarks-of-Robert-F-Kennedy-at-the-University-of-Kansas-March-18-1968.aspx.
15. Marilyn Waring, Counting for Nothing (Toronto: University of Toronto Press, 1999).
16. Joseph E. Stiglitz, Amartya Sen, and Jean-Paul Fitoussi, Mis-measuring our lives (New York: The New Press, 2010).
17. Although they are not a standard part of the NIPA, BEA has made estimates of the value of household production. See Benjamin Bridgman and others, “Accounting for Household Production in the National Accounts, 1965-2010,” Survey of Current Business (92) (2012).
18. Stiglitz, Sen, and Fitoussi, Mis-measuring our lives, page 2.
19. Piketty, Thomas, Emmanuel Saez, and Gabriel Zucman, “Distributional National Accounts: Methods and Estimates for the United States.” Quarterly Journal of Economics (2018, forthcoming).
20. “Major Recurring Reports,” available at https://www.cbo.gov/about/products/major-recurring-reports#15 (last accessed March 18, 2018).
21. “Income Inequality,” available at https://www.census.gov/topics/income-poverty/income-inequality.html (last accessed March 18, 2018).
22. “Consumer Expenditure Survey,” available at https://www.bls.gov/cex/ (last accessed March 18, 2018).
23. “Survey of Consumer Finances (SCF)” available at https://www.federalreserve.gov/econres/scfindex.htm (last accessed March 18, 2018).
24. Income distribution for particular states could be constructed using the Census Bureau’s American Community Survey, but there aren’t official economic statistics, and these numbers would not be comparable to growth nationwide, as they would not be linked to any measure of national income.
25. Atkinson et. al. track the gender integration of the top 10 percent, for example, demonstrating that women are infiltrating the ranks of the very rich slower than they are the merely well-off. See Anthony Atkinson, Alessandra Cesarico, and Sara Voitchovsky, “Top Incomes and the Gender Divide.” Working Paper (LSE International Inequality Institute, 2016).
26. See also Dennis J. Fixler and others, “A Consistent Data Series to Evaluate Growth and Inequality in the National Accounts,” Review of Income in Wealth (63) (2017).
27. Dennis J. Fixler and others, “Toward National and Regional Distributions of Personal Income,” Survey of Current Business (97) (2017).
28. A good discussion is available in Thomas Piketty, Emmanuel Saez, and Gabriel Zucman, “Distributional National Accounts: Methods and Estimates for the United States Data Appendix,” available at http://gabriel-zucman.eu/usdina/ (last accessed March 19, 2018), including the authors’ response to researchers who have made different choices about dividing up income.
29. U.S. Code 26 § 6103(j)(1)(B), Confidentiality and disclosure of returns and return information.
30. Commision on Evidence-Based Policymaking, “The Promise of Evidence-Based Policymaking” (2017), available at https://www.cep.gov/content/dam/cep/report/cep-final-report.pdf (last accessed March 18, 2018).
31. Facundo Alvaredo, and others, “Distributional National Accounts Guidelines” (World Wealth and Income Database).
32. “OECD Better Life Index,” available at http://www.oecdbetterlifeindex.org/ (last accessed March 18, 2018).
33. Jorrit Swijnenburg, Sophie Bournot, and Federico Giovannelli, “Expert Group on Disparities in a National Accounts Framework: Results from the 2015 Exercise.” Working Paper 2016/10. (OECD Statistics, 2017).
34. “Australian National Accounts: Distribution of Household Income, Consumption and Wealth, 2003-04 to 2014-15” available at http://www.abs.gov.au/ausstats%5Cabs@.nsf/0/2A7665F5A468C0F7CA257D65001C105F?Opendocument (last accessed March 18, 2018).
35. “Economic well-being, UK: July to September 2017,”available at https://www.ons.gov.uk/peoplepopulationandcommunity/personalandhouseholdfinances/incomeandwealth/bulletins/economicwellbeing/julytoseptember2017 (last accessed March 18, 2018).
36. Piketty, Saez, and Zucman provide both pretax and post-tax and transfer NNI and discuss their tax incidence assumptions in Thomas Piketty, Emmanuel Saez, and Gabriel Zucman, “Distributional National Accounts: Methods and Estimates for the United States Data Appendix,” available at http://gabriel-zucman.eu/usdina/ (last accessed March 19, 2018).
37. Jonathan Fisher and others, “Inequality in 3D: Income, consumption, and wealth.” Working Paper (Washington Center for Equitable Growth, 2016).
38. These methodological concerns are significant enough that academics continue to disagree about whether consumption inequality is stable or increasing in the United States. Attanasio, Hurst, and Pistaferri attempt to combat measurement error in the CE and find that consumption inequality is increasing. See Orazio Attanasio, Erik Hurst, and Luigi Pistaferri. “The Evolution of Income, Consumption, and Leisure Inequality in the U.S., 1980-2010.” Working Paper 17982 (National Bureau of Economic Research, 2012). These results have recently been called into question again, however, by Olivier Coibion, Yuriy Gorodnichenko, and Dmitri Koustas, “Consumption Inequality and the Frequency of Purchases.” Working Paper 23357 (National Bureau of Economic Research, 2017).
39. See, for example, Kevin J. Furlong “Distributional Estimates in the National Accounts: USA,” presentation before the OECD Expert Group on Disparities in National Accounts, May 28-29, 2015. Furlong finds that matching the Consumer Expenditure Survey to the CPS produces a negative savings rate for the majority of the population.
40. Stiglitz, Sen, and Fitoussi, Mis-measuring our lives, page 2.